How to Extract Metadata from Websites Using FOCA for Windows
at is most likely to work against that site or network.
In
this tutorial, we will looking at FOCA's ability to find, download, and
retrieve files from websites with the file's metadata.
This
metadata can give us insight into such information as the users (could
be critical in cracking passwords), operating system (exploits are
OS-specific), email addresses (possibly for social engineering),
the software used (once again, exploits are OS-, and more and more
often, application-specific), and if we are really lucky, passwords.
When
you install FOCA, you will greeted with a screen like that below. The
first task we need to do is to start a new project and then tell FOCA
where we want to save our results.
Click on image to enlarge. I created a new directory at c:\foca
and will save all my results there. Of course, you can save your
results wherever is convenient for you, or use the default temp
directory.
Step 3Create a Project
In
this tutorial, I will be starting with a project named after the
information security training company, SANS, which is located at sans.org, and I will be saving my results to c:\foca.
Step 4Getting the Metadata
Once I create my project, I can go to the object explorer to the far left and select Metadata.
This enables us to pull the metadata from the files on the website that
contain metadata. Files such as .pdf, .doc, .xls, etc. all contain
metadata that could be useful in your hack of your target.
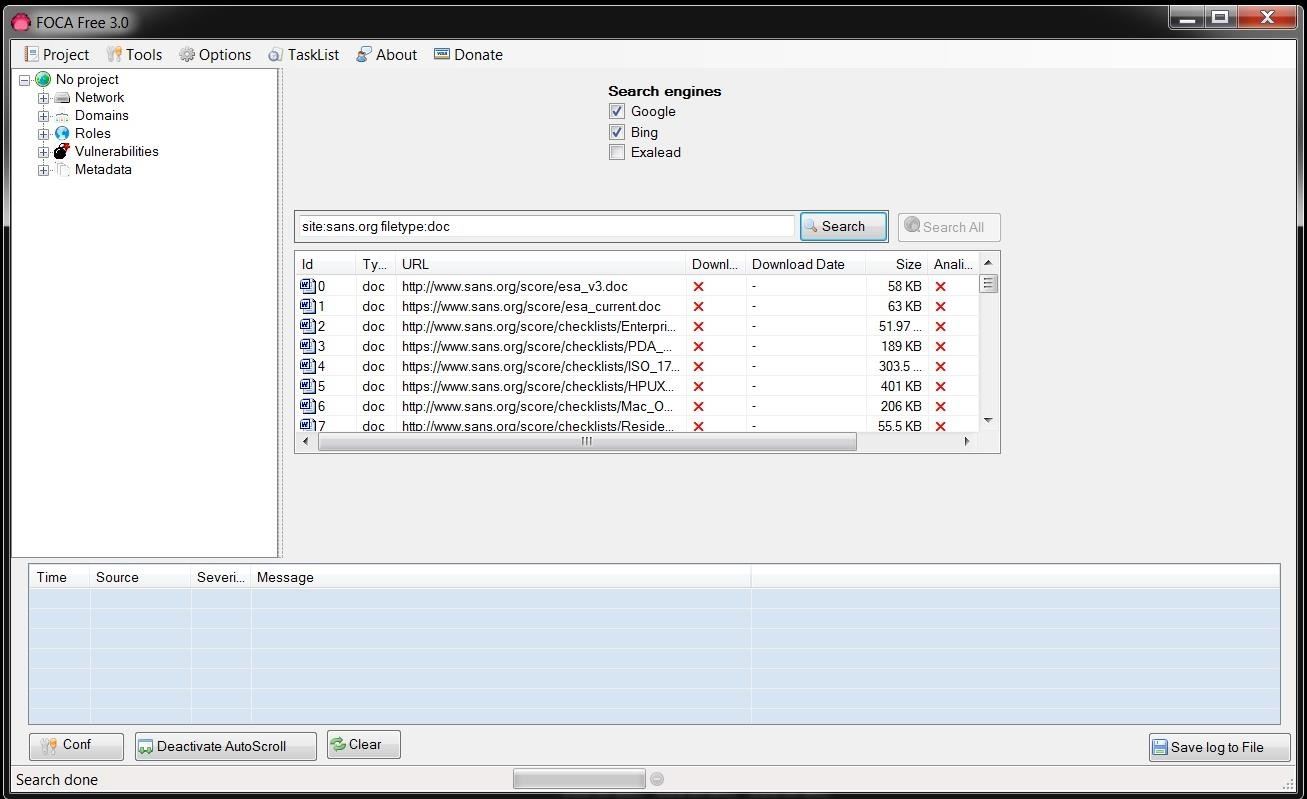
When
you select metadata, you will pull up a screen like that below. In our
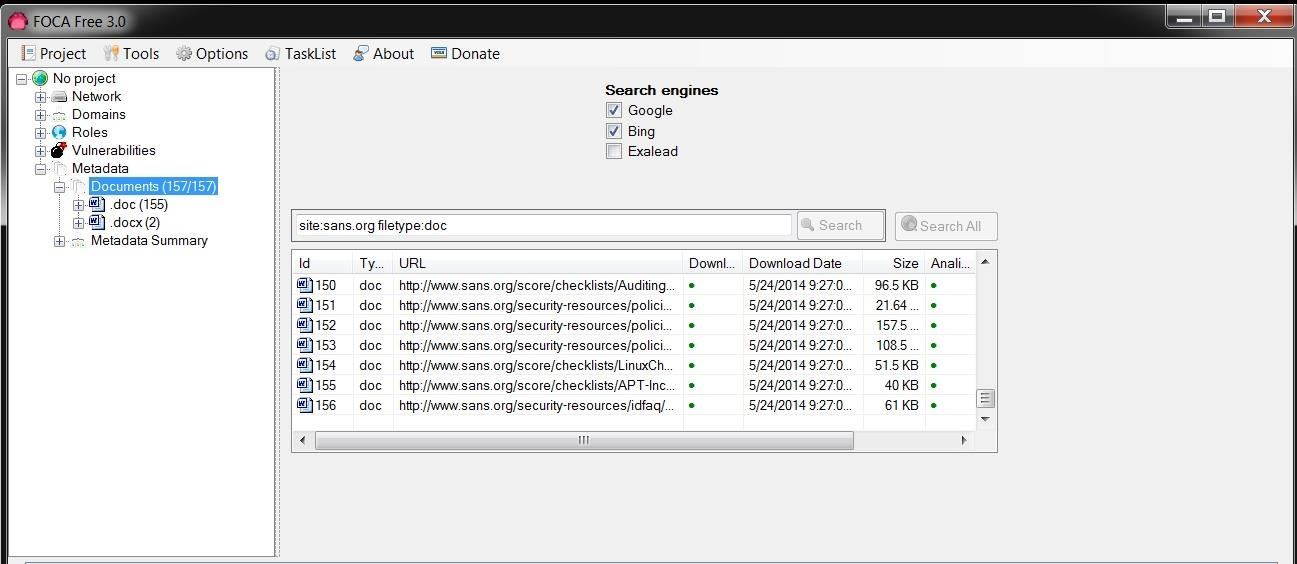
case here, we will be searching sans.org for .doc files, so the syntax
to be placed in the search window is: site:sans.org filetype:doc
This will search the entire sans.org website, looking for .doc files. When I hit the Search button next to the window, it will begin to search and find all the .doc files at sans.org.
Of
course, if you were searching for .pdf files or other filetypes, you
would put in that filetype. You can also search for multiple filetypes
by listing them after filetype, such as: site:sans.org filetype:pdf,doc,xls
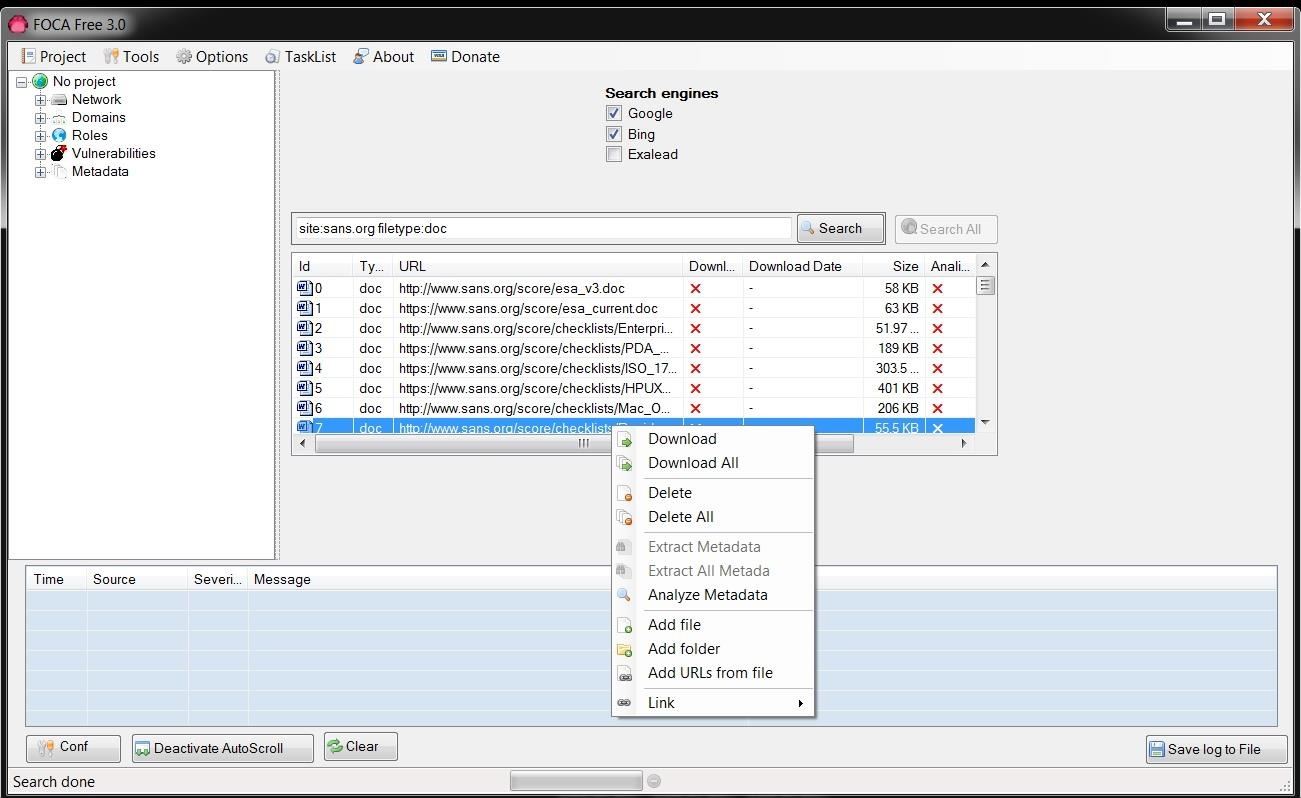
Step 5Download the Files
Once
FOCA is done retrieving a list of all the .doc files, we can then
right-click on any file and download the file to our hard drive,
download all the files, or analyze the metadata. I chose to download all
the .doc files I found at sans.org.
Step 6Collect & Analyze the Metadata
Now
that we have downloaded all the .doc files, I chose to analyze all the
metadata in them. Microsoft's Office files collect significant amounts
of data as they are being created and edited that we can then extract.
When we expand the Metadata folder in the object explorer, you can see that we have 156 .doc files and 2 .docx files.
The Types of Metadata Collected
Just beneath the Metadata documents folder is another folder titled, Metadata Summary.
We can click on it and it reveals the type of metadata is has collected
from the files. This metadata is broken into eight (8) categories:
Users
Folders
Printers
Software
Emails
Operating Systems
Passwords
Servers
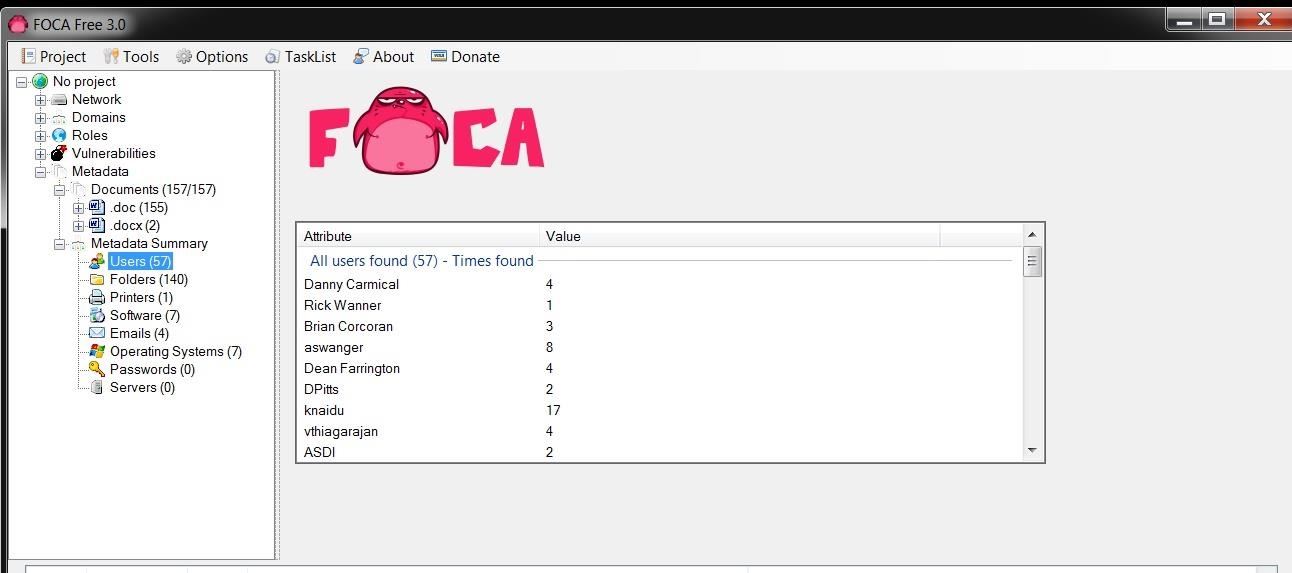
Let's take a look at Users first. When we click on users, we can see that FOCA has collected the names of every user that worked on those files.
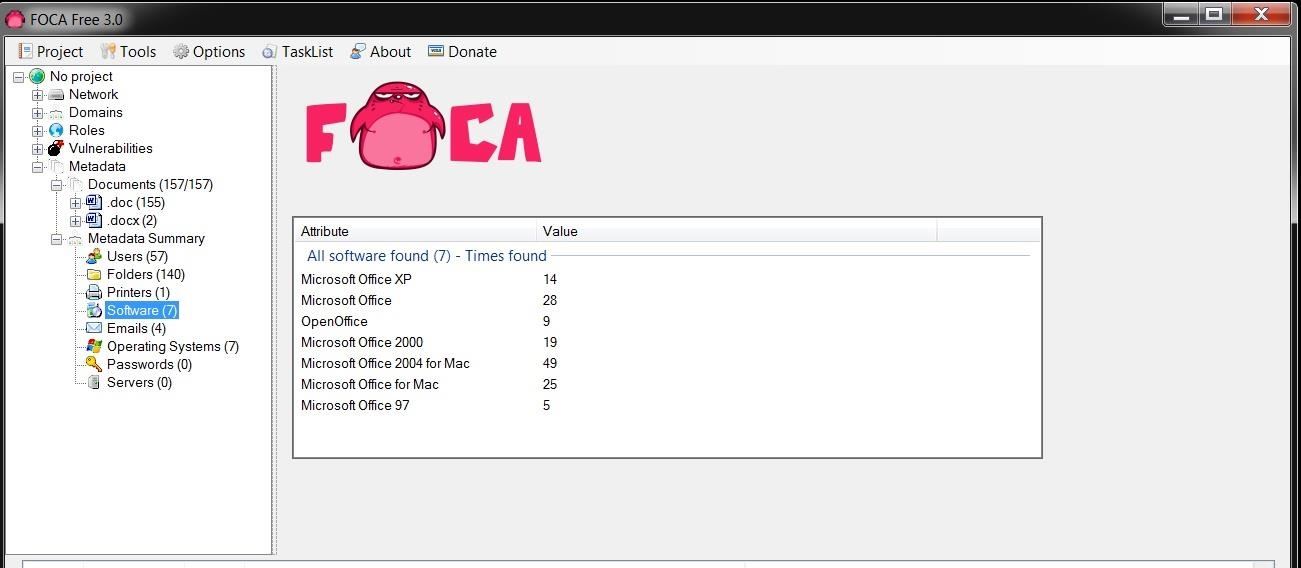
When we click on Software,
we can see the various editions of Microsoft Office that has been used,
including five (5) users that created their documents with Office '97
(hmm...wonder if there are any Office '97 vulnerabilities still out
there?).
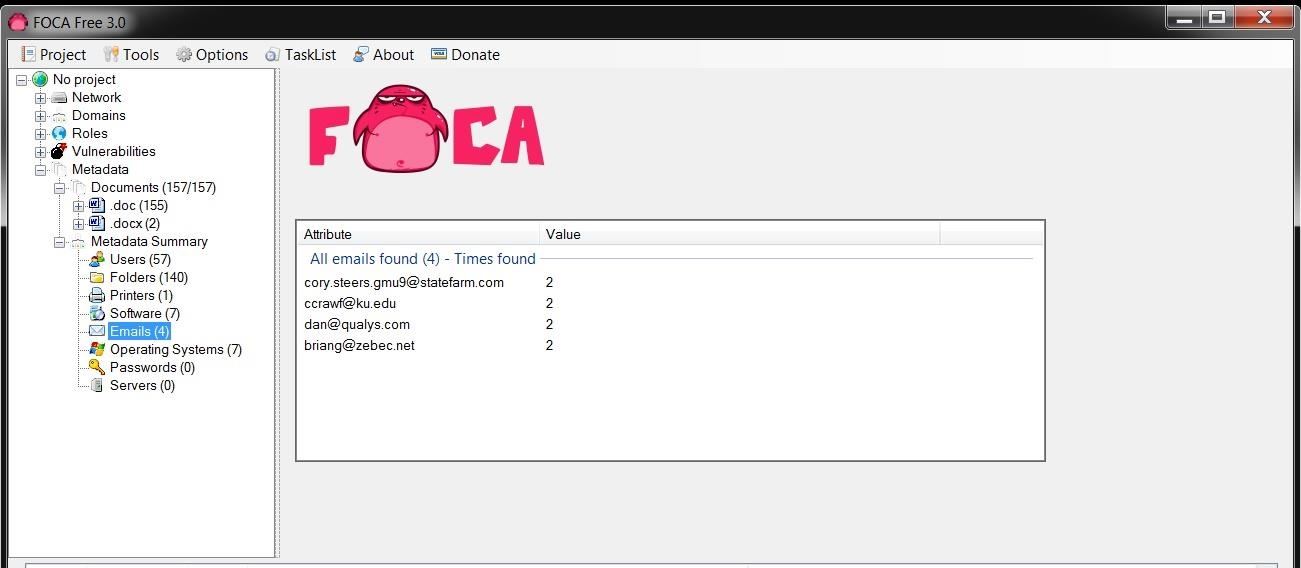
We
can also look for email addresses that are embedded in the documents as
displayed below. Obviously, these folks are making themselves available
to a social engineering attack.
We
can also gather printer, folder, passwords, and servers from this
metadata depending upon the documents we recover. All of this
information can then be used to determine what is the best attack
against this organization/website.